Over the last few years, there has been an on-going, vigorous debate regarding the future of artificial intelligence (AI) and machine learning (ML), and what needs to be developed. The debate comes down to using only machine learning technologies (based on different mathematical models and performing correlation/pattern analysis) versus using a combination of machine learning and "classical AI" (i.e., rules-based and expert systems). (Note that no one believes that rules-based systems alone are enough!) You can read about those debates in numerous articles (such as in the MIT Technology Review, ZDNet's summary of the December 2020 second debate, and Ben Dickson's TechTalks).
Given my focus on knowledge engineering, I tend to land on the side of the "hybrid" approach (spearheaded by Gary Marcus in the debates) that combines ML and classical AI, and then I add on ontologies (to provide formal descriptions of the semantics of things and their relationships and rules).
As a bit more background, Stephen Pinker's book, How the Mind Works, describes this hybrid approach when explaining how people think. "People think in two modes [fuzzy stereotypes with correlations, and systems of rules]. They can form fuzzy stereotypes by uninsightfully soaking up correlations among properties, taking advantage of the fact that things in the world tend to fall into clusters (things that bark also bite and lift their legs at hydrants). But people can also create systems of rules - intuitive theories - that define categories in terms of the rules that apply to them, and that treat all the members of the category equally ... Rule systems allow us to rise above mere similarity and reach conclusions based on explanations."
Pinker later makes this more explicit when he writes, "We treat [things like] games and vegetables as categories that have stereotypes, fuzzy boundaries and family-like resemblances. That kind of category falls naturally out of pattern-associator neural networks. We treat [other things like] odd numbers and females as categories that have definitions, in-or-out boundaries and common threads running through the members. That kind of category is naturally computed by systems of rules."
We can now ask how Deep Narrative Analysis (DNA) uses this hybrid approach and combines machine learning and natural language processing components, classical AI/rules and ontologies. The figure below shows how DNA brings these technologies together. The entities in grey are based on existing ML, ontology and rules-based tooling, while the entities in yellow are developed by OntoInsights to provide semantically-rich understanding.

DNA is developing a system intended to provide "deep understanding". This is a term used by Gary Marcus in his paper,
The Next Decade in AI. It involves both pattern analysis and "the capacity to look at any scenario and address questions such as a journalist might ask: who, what, where, why, when, and how". DNA's scenarios are built from narratives, and are given deeper insights and organization by our
event-focused ontology. The events in a narrative are used to create a "cognitive model" of the narrator's world, that is updated as the text proceeds. ML technologies contribute hugely in parsing the text to obtain the scenarios (using grammatical patterns) and then later in the analysis process to find supporting/refuting patterns and similarities/differences in the data.
But, what is a "cognitive model"? Returning to Gary Marcus'
Next Decade in AI paper, he writes ... "Many cognitive scientists, including myself, view cognition in terms of a kind of cycle: organisms (e.g. humans) take in perceptual information from the outside, they build internal cognitive models based on their perception of that information, and then they make decisions with respect to those cognitive models, which might include information about what sort of entities there are in the external world, what their properties are, and how those entities relate to one another. Cognitive scientists universally recognize that such cognitive models may be incomplete or inaccurate, but also see them as central to how an organism views the world (Gallistel, 1990; Gallistel & King, 2010). Even in imperfect form, cognitive models can serve as a powerful guide to the world; to a great extent the degree to which an organism prospers in the world is a function of how good those internal cognitive models are."
ML-based text processing is not enough to provide "deep understanding" or to create "cognitive models". However, they are excellent at:
- Part of speech tagging
- Finding relationships between words/clauses of a sentence (as found with dependency parsing)
- Named entity recognition of persons, organizations, places, events, dates, etc.
- Correlation of words from a corpus (such as accomplished using GPT-2 and -3)
They provide valuable insights and certainly build on correlations between words, but those are very shallow understandings.
Our current work analyzes Holocaust narratives published by the
US Holocaust Museum. The following sentence is extracted from Erika Eckstut's biography in
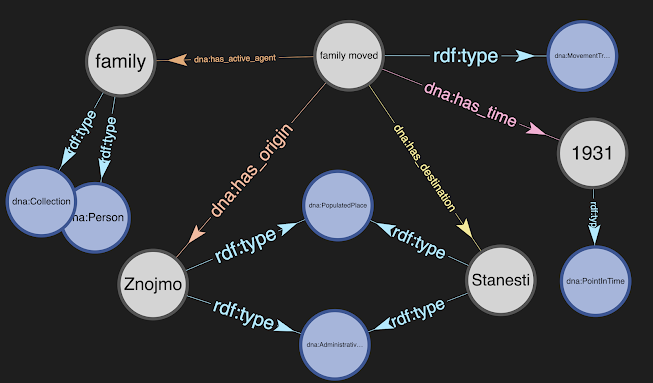
Echoes of Memory, Vol 1 ... "When Romania joined Nazi Germany in the war against the Soviet Union, the Soviets were driven from Stanesti." The ML-, transformer-based spaCy tooling (
v3) can easily analyze the sentence. It can correctly report that Romania, Stanesti and the Soviet Union are geo-political entities, that Nazi Germany and the Soviets are organizations/groups, that the clause, "when Romania joined Nazi Germany", modifies the statement, "the Soviets were driven from Stanesti", etc. Perhaps with enough training data, ML would also indicate that Stanesti is usually associated with Romania. But, indicating a correlation is not understanding. The fact that Stanesti is in Romania can easily and unambiguously be obtained by querying
GeoNames (to learn that Stanesti is a second-order administrative region in Romania). Then, knowing that Romania was fighting against the Soviet Union (and allied with Nazi Germany) gives deeper meaning ("understanding" as to) why the Soviets left the city.
But, how does DNA determine that the phrase, "the Soviets were driven from Stanesti", mean that the Soviets left the city? In DNA, the text is initially evaluated using the concepts encoded in
VerbNet (which is a human-curated lexicon that defines and links the syntactic and semantic patterns of many English verbs). The VerbNet entries for "drive" deal with moving someone or something or compelling/forcing someone to do something. Those definitions are essentially correct (but certainly could be further refined) since the Soviets were forced to move from Stanesti (and even likely withdrew using motor vehicles!). So, the semantics are captured using the DNA Ontology's Event classes, MovementTravelAndTransportation and CoercionAndIntimidation. Both the DNA Ontology and the mapping of a sentence to its Events and StatesAndConditions can be further refined by human review and by the addition of knowledge using rules-based inference. Those rules can address ethical and common sense concepts (extracted from human-curated sources such as
ConceptNet and
ATOMIC), and/or add scientific knowledge. Encoding and evaluating the rules are tasks easily supported by the
Stardog Server which is a key component of DNA's architecture.
DNA does not intend to remove the need for human interaction. Indeed, a user can tune the system much as a teacher or parent explains and improves the understanding of a child. And, when a user improves results, DNA saves the details of the changes, which are then reviewed to determine if new rules or different processing can derive better understanding.
Going beyond "understanding", DNA is designed to support research (specifically focusing on
grounded theory research). Briefly, the goal of DNA is to enable the creation (discovery) of theories/hypotheses explaining what is observed in both the qualitative narrative data and quantitative background information accessed from online and linked data sources, using comparative analysis. That analysis starts with examining and splitting the data searching for key concepts, and then searching for similarities and differences in the relationships between the concepts. Those searches and analyses may highlight the need to gather further narratives, or to split the data in different ways. Taking this approach, the data is iteratively analyzed and the hypotheses refined.
All of this makes the DNA application so much more than an exercise in ML. It is an application firmly centered in Gary Marcus' "hybrid" architectures "that combine symbol manipulation with other techniques such as deep learning ... Deep learning has raised the bar for learning, particularly from large data sets, symbol manipulation has set the standard for representing and manipulating abstractions. It is clear that we need to bring the two (or something like them) together". DNA is striving to do just that!

Comments
Post a Comment