Creating the Narrative Analysis Demo
Over the last month, OntoInsights has developed a prototype application to analyze human narratives, utilizing linguistic and semantic theory, and building on open-source offerings in machine learning and natural language processing. The application shows how the concepts behind Deep Narrative Analysis (DNA, as discussed in our first blog post, The Power of Narrative) can automatically convert stories in the form of unstructured text, into machine-analyzable knowledge graphs that retain all their richness.
In this blog post, we overview the structure of the DNA application (which is available in the dna directory of our project on GitHub). You might be interested in the structure if you want to review or reuse our code to process PDFs and unstructured text, get background Wikidata, create a simple GUI, and more.
Our approach to development is to start by encoding the basics of a design approach or algorithm in a Jupyter notebook, or use a notebook to generate the knowledge/triples for background data. Looking at the notebooks directory on GitHub, you can see that we have been experimenting with:
- Converting 'background' data (as noted in the sub-bullets) to RDF triples for storage in a knowledge graph
- Lists of religions and ethnicities found in PDFs (see Example_Process_PDF)
- Details about a country from the GeoNames API (see Backgrd_Get_CountryInfo)
- A glossary of terms from a web page of the US Holocaust Museum (see Backgrd_Holocaust_Glossary)
- Creating dictionaries from the VerbNet xml files to allow DNA to match sentence structures to the VerbNet Frame details and thereby extract semantic meaning (see Backgrd_VerbNet)
- Also creating lists of all VerbNet predicate and argument semantics to ensure that DNA accounts for the possible semantics that will be found in these dictionaries (see Backgrd_VerbNet_Terms)
- Using spaCy for dependency parsing, sentence simplication and more (see Example_Playing_with_spacy and Example2_spacy)
- Using the Stardog triple store via the pystardog library (see Backgrd_Create_and_Load_NarrativesDB)
When the initial results are 'good enough', we then move the code into our prototype application, and test and tweak it further there.
So, what does the DNA prototype application do? And, how does it do it?
DNA is written using a very simplistic front-end based on PySimpleGUI. Our goal at this point is to work on the hard problems of semantic parsing and natural language understanding (NLU), and not to create an award-winning interface. (That will come later.) So, the interface is clunky but it shows what we want to do:
- Ingest narratives and create knowledge graphs from them, so that comparisons can be done and new data inferred
- Experiment with the various capabilities of spaCy (such as its rule-based matching, dependency parsing and entity recognition)
- Display information about the narrators, so that a user can understand if the collected narratives adequately reflect a population
- Show a timeline of a narrative, so that (in the future), timelines for narratives, news events and interventions can be overlaid and correlated
- Show similarities between narratives
- Define 'hypotheses' and find supporting and refuting evidence in the narrative
- We define hypotheses as lists or series of events, conditions and requirements (such as the gender or education level of the narrator)
- They are searched for, in the narratives and the narrators' metadata
- Search allows both querying for the occurrence of events and conditions in any order, or for their occurrence in a specific sequence
- Results of searching the narratives indicate the ones where the hypothesis is supported (e.g., where the events, conditions or requirements are found) and the ones where the hypothesis is not found
- Initially, summary statistics will be displayed for the supporting/refuting narratives to aid in expanding or restricting the hypotheses, but it is assumed that much deeper analyses will eventually be included
The application's startup screen is shown in the figure below. Each of the tasks above is represented by a button, and pop-up help text is shown by clicking on the question mark to the right of the button. All the help text is found in the help.py file in the dna directory, and serves as our roadmap for building out functionality.

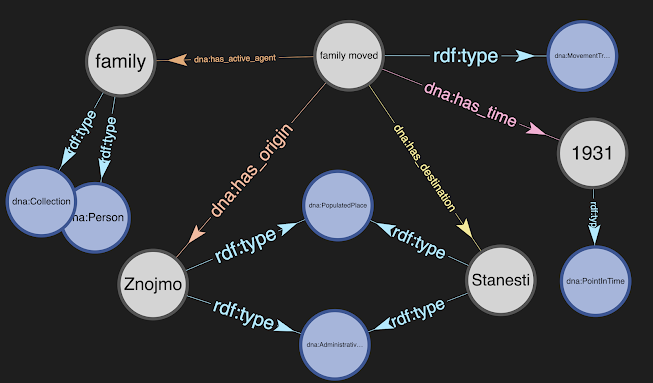
At this time, we are working on the core functionality and only the first four buttons are functional. For example, we have successfully used spaCy's dependency parsing to output a narrative timeline. An example is shown below. The output is promising but is still basic with errors and missing information. Also, we need to change the output from text to triples in a knowledge graph. That is our goal for our work in June.

One last item to note is that the DNA prototype includes testing (see the GitHub project's tests directory) and code coverage metrics (in the htmlcov subdirectory of tests). We aren't there yet, but we want 90% coverage on all processing (e.g., non-GUI) modules. (In today's code, that would be the database, load and nlp files, and portions of the details_xxx files.)

Comments
Post a Comment